Building iOS Mobile Apps with Redux-like Architecture

#iOS App Development, #Software Engineering
If you had a chance to watch one of the WWDC-2020 videos called Data Essentials in SwiftUI, you probably paid attention to the following image, describing the data flow in SwiftUI.
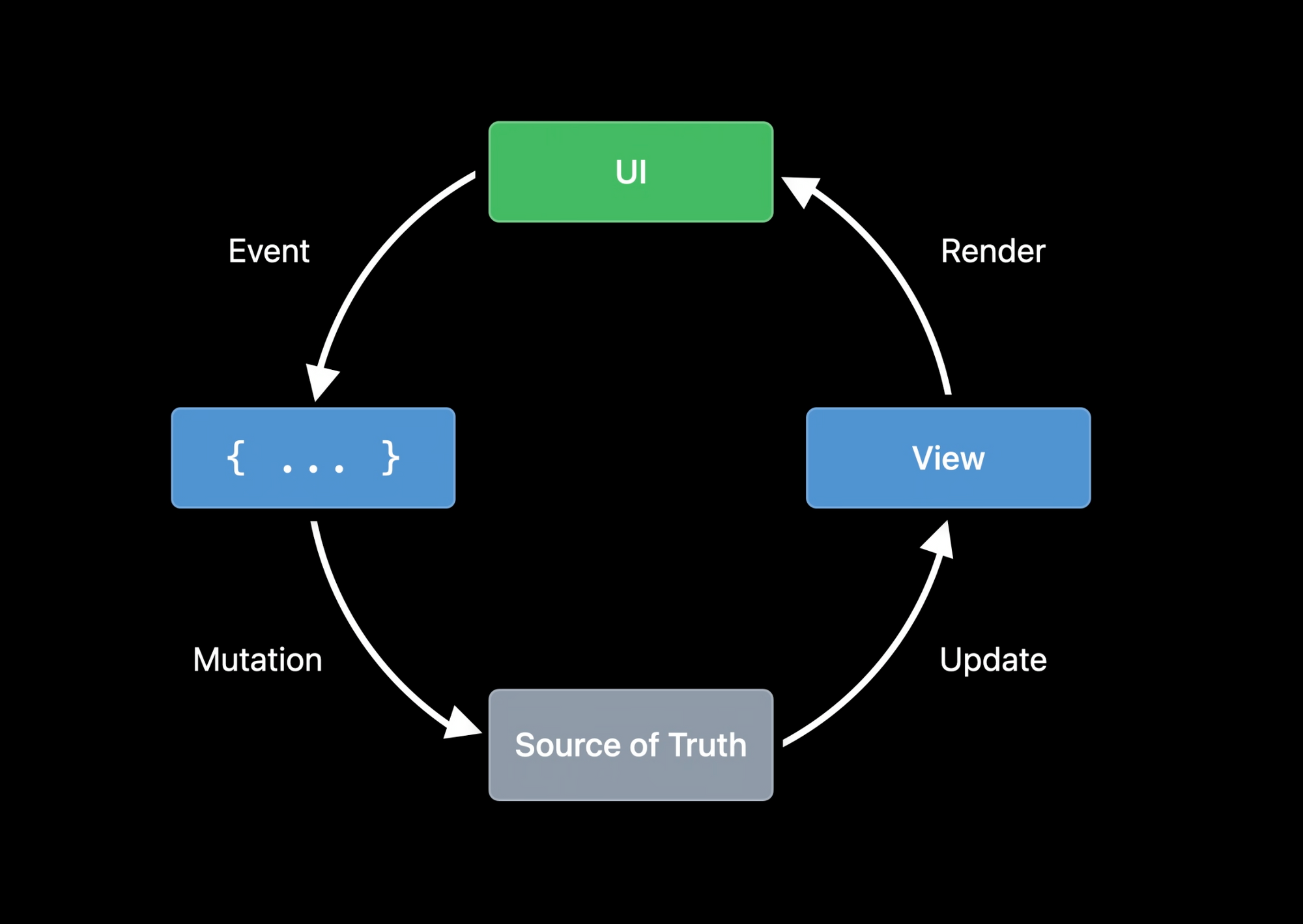
Actually, this is the exact illustration of the idea of a unidirectional data flow (UDF) architecture. SwiftUI suggests that the whole loop is taking place right in the UI layer of the app.
A couple of suggestions:
- What if we could decouple that UDF pattern from UI layer, decompose and leverage it up to an app scale?
- What if we introduce abstractions for all events so that every mutation in the app would be explicit and could be treated like a distinct transaction?
Actually, it has been done long ago in web apps. Furthermore, it has become so popular among web frontend devs that I have no idea how it managed to gather almost zero attention among iOS folks for a long time.
Origins
In 2014 Facebook introduced architecture design pattern which they called Flux. Flux was to tackle the complexities of managing the state in large-scale front-end applications.
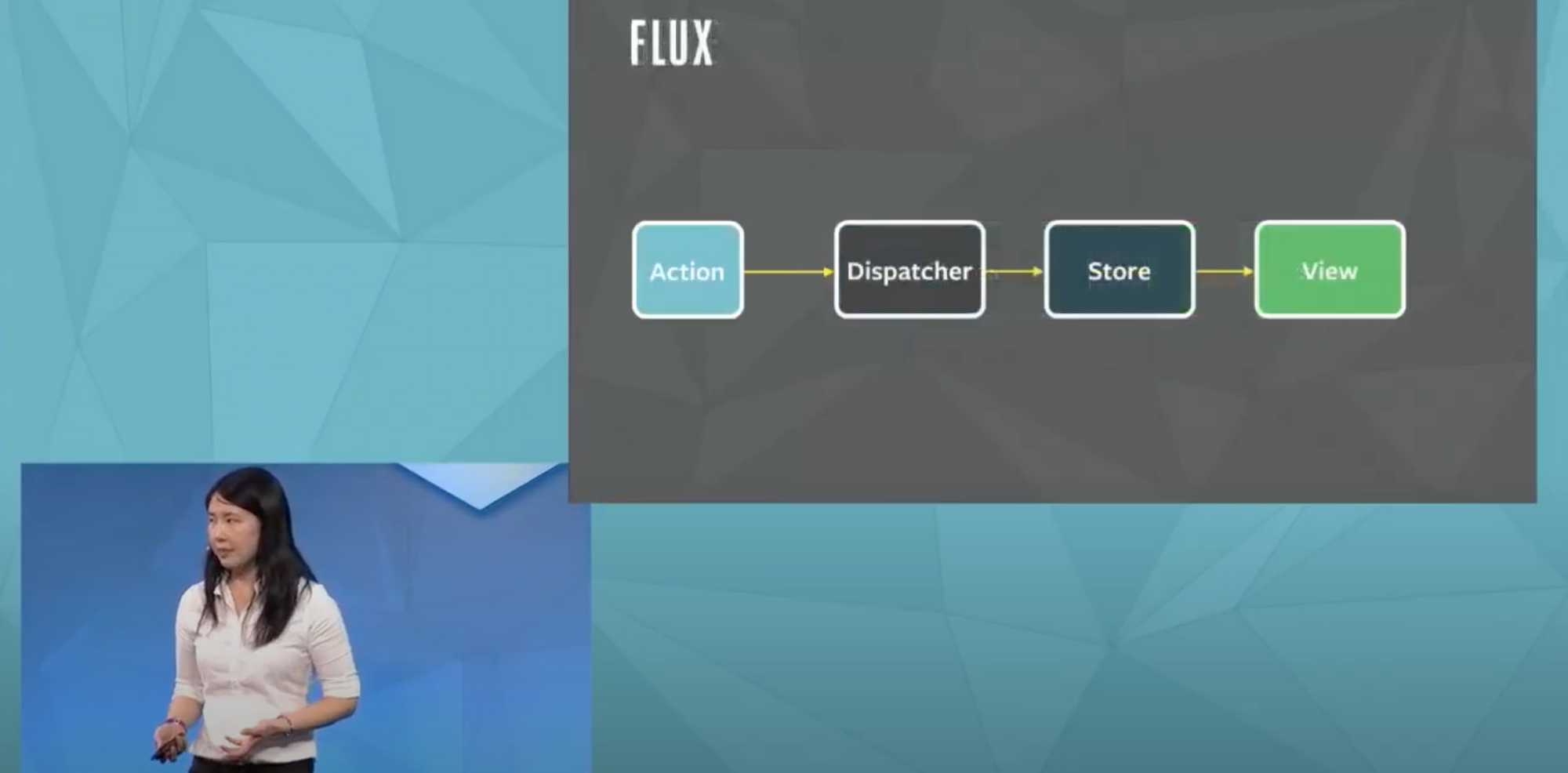
Later the ideas used in Flux became the basement for tons of libs and frameworks for state management in web apps' frontend.
Redux turned out to be one of the most famous. So famous that it's often used as the name of the pattern along with UDF (unidirectional data flow architecture) or MVI (Model-View-Intent), or Elm which is a programming language with UDF in its mind.
Design Overview
Here is a list of components that are commonly used in Redux-like MVI architectures:
- View
- Props
- Actions
- State
- Dispatcher
- Reducer
- Store
- Side Effects
Views and Props
The view is to be implemented in particular way. It should data-driven with only one entry point, which is usually a render function with a single input that is called Props:
func render(_ props: Props) { ... }
In iOS terms in the case of a SwiftUI app we can use a view constructor instead of a render function due to the SwiftUI-specific view lifecycle:
extension SomeView {
struct Props {
let title: String
let subtitle: String
let selection: () -> Void
}
}
struct SomeView: View {
let props: Props
var body: some View {
VStack {
Button(props.title) {
props.selection()
}
Text(props.subtitle)
}
}
}
In the case if UIKit we can either do it on the UIView level:
extension SomeView {
struct Props {
let title: String
let subtitle: String
let selection: () -> Void
}
}
final class SomeView: UIView {
private var props: Props?
init(frame: CGRect) {
super.init(frame: frame)
//setup view here
}
func setProps(_ props: Props) {
//update view here
}
private lazy var body: UIView = {
//setup view body here
}()
}
Or UIViewController:
final class SomeScreenViewViewController: UIViewController {
private let body = SomeView(frame: .zero)
func setProps(_ props: SomeView.Props) {
body.setProps(props)
}
override func viewDidLoad() {
super.viewDidLoad()
view.addSubview(body)
//setup view body here
}
}
The main trick about data-driven View is that the entire view's state is represented by a single DTO that contains all prepared information that may be shown to the user directly without changes.
We sometimes call them "view models", but in the Redux world it's called Props.
The Difference Between Props & ViewModel
It's easy to confuse with MVVM's ViewModel where VM is a sort of a handy guy who is usually bound to a View, has a mutable state inside, executes some presentation logic, and can do many things.
In contrast, Props is simple data. Props are meant to be just lightweight view models DTOs.
- If we need to handle user inputs or touch events we do it by closures that are passed as Props's properties.
- If we need to do animations it's up to the View entirely: it may diff the old state with new Props and behave accordingly.
Complex UI components may be a composition of simple ones, the same can be said about Props.
Actions
Every event that is taking place within the app is wrapped into Action. User text inputs and taps, server responses, etc. They are sometimes called "Intents" in the MVI architecture pattern or simply "Events". It's all the same thing.
What matters is that we introduce a separate abstraction for every possible change in the app state, which acts like a transaction.
State
The core idea is to implement UI declaratively as a function of state. That's exactly what we are doing when we use SwiftUI.
In Redux, the single state is considered a data representation of the whole app. It may include not only business entities, auth state, etc but also UI and state of navigation. There are Flux-like alternatives, which suggest using multiple states that correspond to different features of the app.
Since state mutation is a bit expensive because it requires a round trip for actions dispatch and causes the UI update cycle, there are debates about: "What exactly should we put into the state?".
-
Some opinions insist on putting exactly everything into the store-managed state, only mutating it with actions, and keeping the rest of the app stateless.
-
Other devs suggest putting things into a store-managed state depending on their lifecycle and scope of use.
There are other state design caveats. For example, how to denormalize it and how to properly design the state of navigation.
Dispatcher
All UDF architectures are designed similarly.
Upper layers of the app, like UI cannot mutate the state directly. All they can do is send actions to a Dispatcher.
Originally, Flux was meant to have multiple stores with corresponding multiple states, so Dispatcher was intended to pass actions later on to Stores. The dispatcher handled prioritization and blocking dispatching. Some of the stores could wait for other stores to finish their work.
Redux is designed a bit differently. It's more simple. Since there is a single store the Dispatcher passes actions to the store and that's it. Store only ensures that actions are queued up and handled serially.
Reducer
Reducer is the only guy who knows how to mutate app state. Traditionally, a reducer is a pure function from state and action as input. It performs mutation and returns a new state.
This may sound a bit awkward, especially in a Redux-like single-state single-store case. As if we need to have a huge switch over all the app actions knowing how to mutate the whole app.
We don't. The app state can be a composition of other substates and the main app reducer can simply pass the actions to the substates' reducers.
So the whole thing can be quite clean:
struct AppState {
private(set) var featureOne = FeatureOne()
private(set) var featureTwo = FeatureTwo()
mutating func reduce(_ action: Action) {
featureOne.reduce(action)
featureTwo.reduce(action)
}
}
Store
The store is the guy who puts together the state, reducer, and dispatcher. It allows observers to subscribe and listen to the state updates.
When action is dispatched to the store, the action is applied to the state through reducer, and then the new state is passed to all store observers.
Side Effects
As you might have already noticed, it's not so obvious where we should put async work: network requests, database fetches and other I/O operations, timer events, location service callbacks, etc.
Things, that in the UDF world are called "side effects".
There are debates about where to put them, no single correct opinion, and several common patterns, that are applied in different combinations in all UDF architecture libraries.
The questions are:
- Who should be responsible for initiation of side effects
- Who should be responsible for executing side effects
- How should the result be delivered
We need to choose a proper place to put the implementation of side effects, how we would execute them, and deliver the result of their work: resulting actions that should be dispatched back to the store.
Different Ways to Handle Side Effects
Async Executable Actions
One of the ways to handle side effects is to introduce a special kind of executable action, like AsyncAction. When dispatched it would be executed at some point, perform some async work, and then dispatch more actions back to the store when the work is done.
Here is a simple example of how it may look like:
// OOP-style Protocol-based Actions and AsyncActions
protocol AsyncAction: Action {
func execute(_ dispatch: @escaping DispatchFunction)
}
struct FetchMoviesList: AsyncAction {
let page: Int
func execute(_ dispatch: @escaping DispatchFunction) {
APIService.shared.fetchMoviesList(page) { result in
dispatch(FetchMovieListResult(result, page: page))
}
}
}
// Here is another example of a more FP-style enum-based Actions implementation:
enum Action {
typealias Execution = (_ dispatch: @escaping Dispatch<Action>) -> Void
case fetchMoviesList(page: Int)
case fetchMovieListResult(Result<[Movies], Error>, page: Int)
var execution: Execution? {
switch self {
case .fetchMovieListResult:
return nil
case .fetchMoviesList(let page):
return { dispatch in
APIService.shared.fetchMoviesList(page) { result in
dispatch(.fetchMovieListResult(result, page))
}
}
}
}
Async actions and their execution are easy to implement. They are close to function call semantically which makes them easy to integrate with asynchronous APIs that use either callbacks or async/await syntax.
Actions naturally align with the use case so there is no extra effort required to pass some specific scope.
Action Creator: Reasons to Use an Actions Factory
Async actions are likely to have dependencies, like API clients or database data sources. Following the [[Dependency Inversion Principle]] we might want to provide dependencies to the action explicitly or somehow inject them.
Since actions can be created at any part of the app, including the UI layer, it may eventually become a mess because we need to pass actions' dependencies here and there.
Creational design patterns like factories and or factory methods can be used to tackle the problem. In Redux toolkit, they use "Action Creator" – a factory method that is used to instantiate different kinds of Actions.
We can do a similar thing is Swift. The idea is to offload the responsibility for constructing Action to someone else. So that the actual "user" of the Action doesn't know how the Action is constructed or even what the exact type it is. It's all covered by the Action protocol.
ActionsFactory could be a candidate for that role:
extension Action {
static func fetchMoviesList(page: Int) -> Action {
// any dependency injection lib can be used here
let moviesService = Dependency[\.moviesService]
let action = FetchMoviesList(moviesService: moviesService,
page: page)
return action
}
}
struct FetchMoviesList: AsyncAction {
let moviesService: MoviesService
let page: Int
func execute(_ dispatch: @escaping DispatchFunction) {
moviesService.fetchMoviesList(page: page) { result in
dispatch(MoviesListFetchResult(result, page: self.page))
}
}
}
With that implementation, we can swap the MoviesService dependency for another implementation for testing or whatever purposes without a need to touch the rest of the app.
Thick Async Actions & Thin Middleware
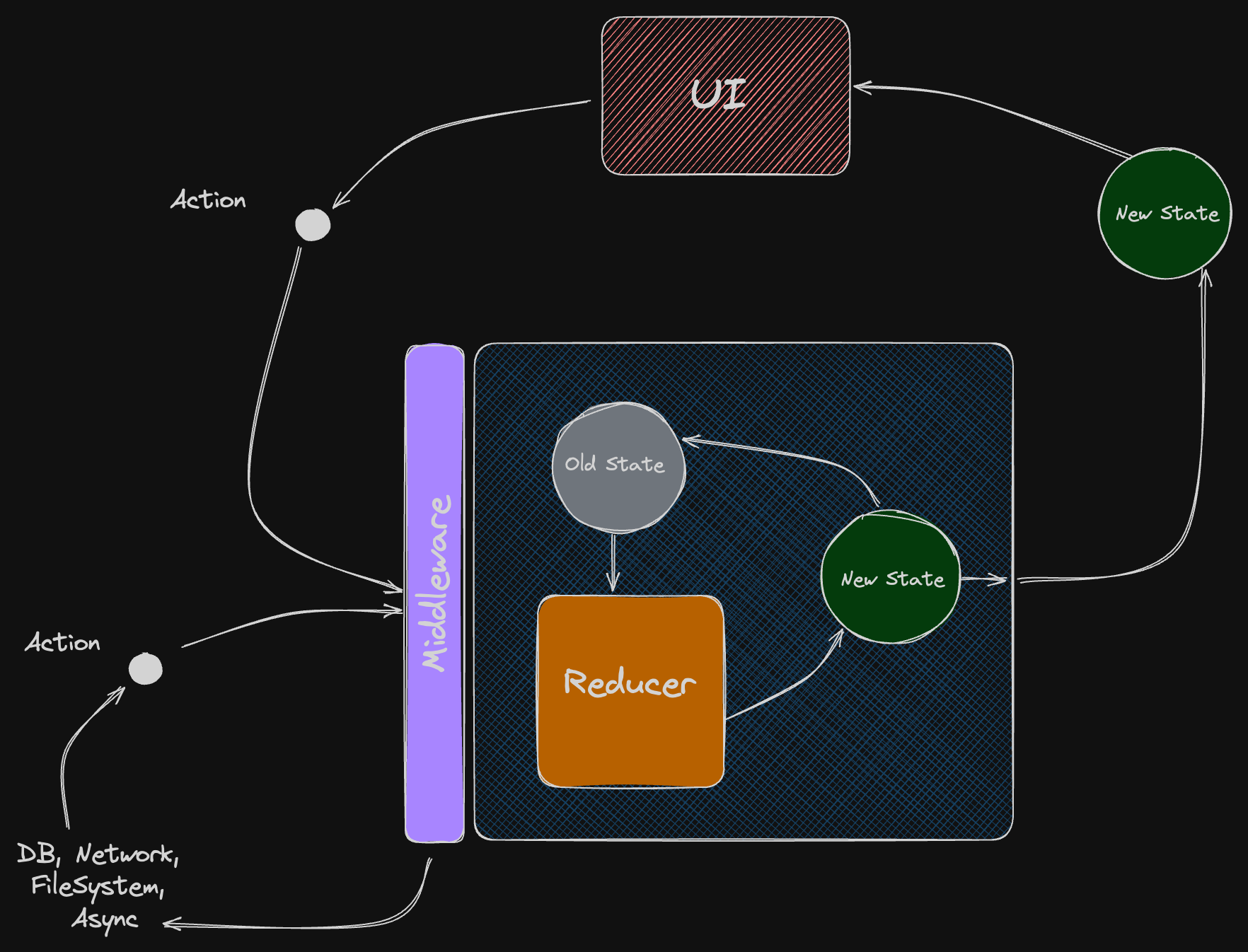
Ok, we have async actions. Now, we need somebody who will execute them. For that purpose, we can introduce Middleware.
Since we've put all the complicated side effect implementation in the async action, we can make Middleware very thin and simple:
struct AsyncActionsMiddleware: Middleware {
let dispatchFunction: DispatchFunction
func intercept(_ action: Action) {
guard let action = action as? AsyncAction else {
return
}
action.execute(dispatch: dispatchFunction)
}
}
Where will we place it?
It's reasonable to put it right into the store in front of the reducer. So that it will receive all the actions, execute async ones, and will be able to dispatch the result actions after the async work is done.
The good thing in this approach is scalability. It's actions' responsibility to handle async work. The middleware doesn't know anything about your features, actual actions, async work nor doesn't have dependencies.
It's fairly easy to intercept an async action behind a protocol. With an enum-based Actions i
The bad thing is it doesn't work that elegant with enum-based Actions. It's easy to intercept and AsyncAction behind a protocol. When dealing with an enum
Thin Async Actions & Thick Middleware
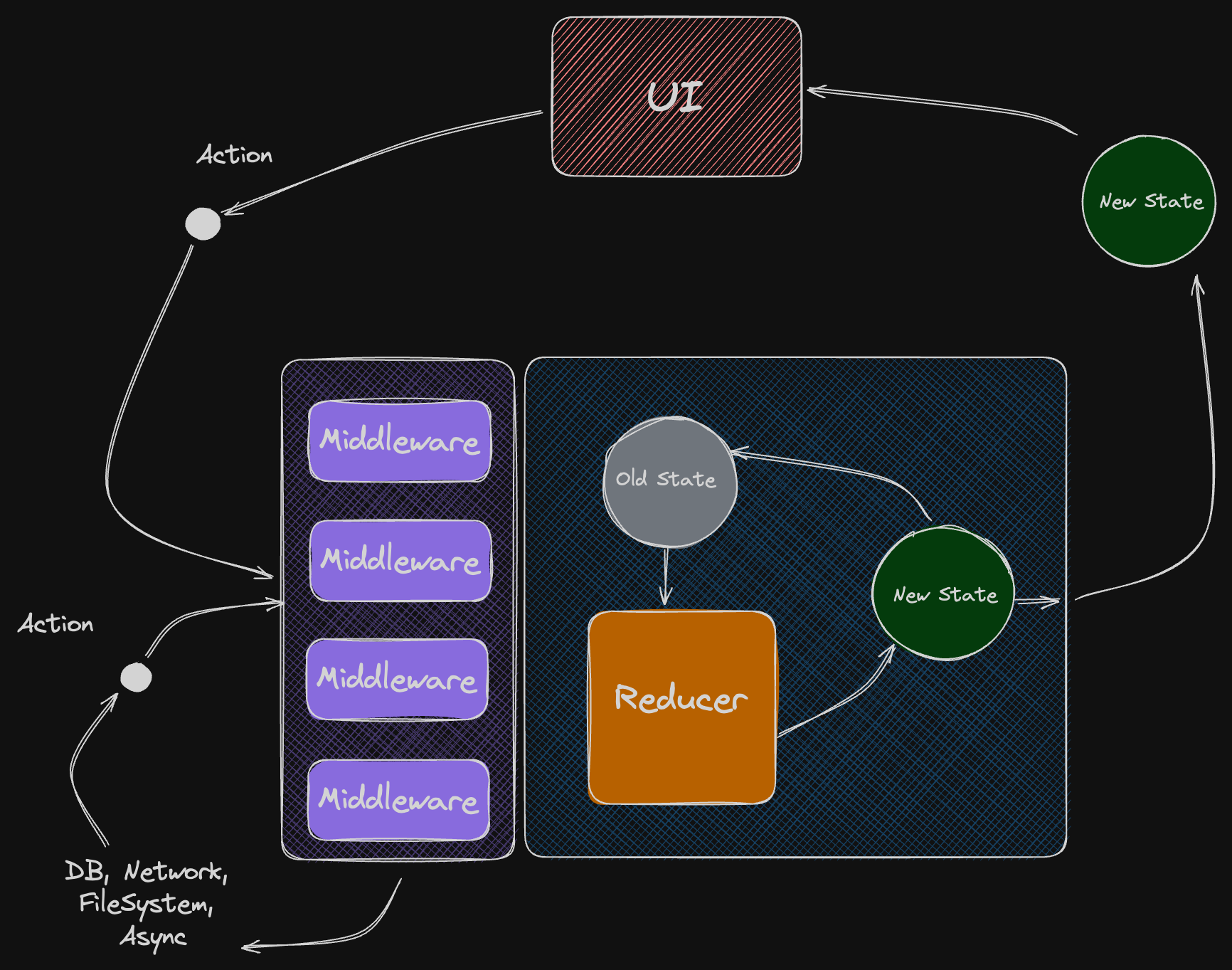
There is another approach. We can make actions dependencies-free and move side effects implementation to the Middleware.
We can allow middleware to intercept exact type of actions or specific action enum cases, decide which AsyncWork to perform, execute it and then dispatch more actions as the result of its work.
Depending on the actions implementation we might need to type cast in case of protocol-based actions:
struct MoviesMiddleware: Middleware {
// dependencies can be passed explicity or via DI
let moviesService: MoviesService
func execute(_ action: Action, dispatch: Dispatch<Action>) {
switch action {
case let action as FetchMovies:
moviesService.fetchMoviesList(page: action.page) { result in
dispatch(MoviesListFetchResult(result, page: action.page))
}
default:
break
}
}
}
Or we can just switch-case for enum-based actions:
struct MoviesMiddleware: Middleware {
// dependencies can be passed explicity or via DI
let moviesService: MoviesService
func intercept(_ action: Actions, dispatch: DispatchFunction ) {
switch action {
case .fetchMovies(let page):
moviesService.fetchMoviesList(page: page) { result in
dispatch(.moviesListFetchResult(result, page: page))
}
default:
break
}
}
}
This approach is pretty damn flexible.
The store may have an array of middleware items as an input. So we can break down large middlewares into smaller ones. We can do it based on app features. We can use specific middleware for logging, analytics, error handling or whatever.
What's important is that for the Middleware we don't even need to rely on dependency injection, use mocks for testing purposes, and so on.
We can just take any set of middleware that we need for a particular use case or test case and plug them into the store.
Async Actions & (State, Action) Middleware
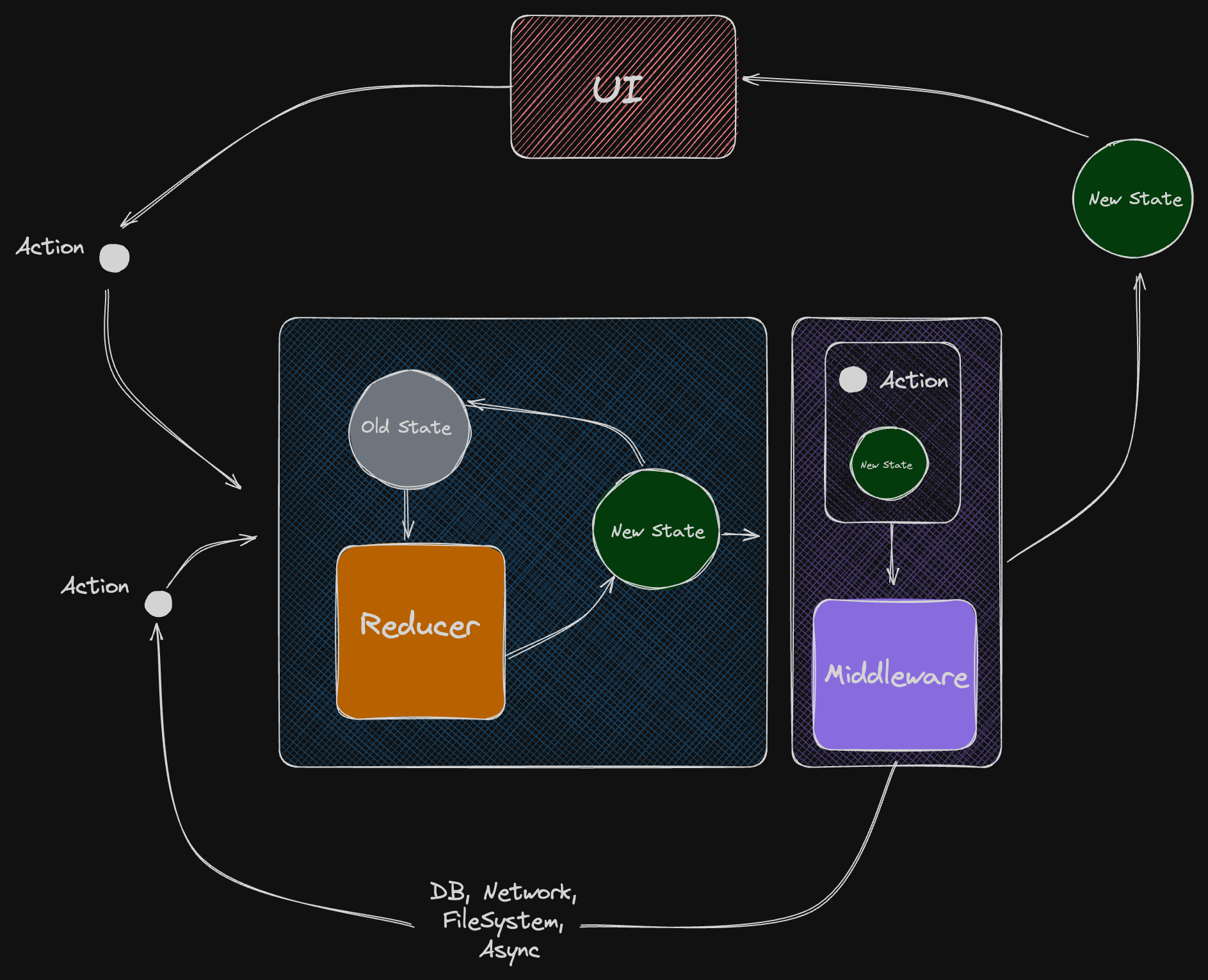
There are cases when we have an intent to execute some sort of a side-effect. But the decision-making logic behind it might be complicated and depend heavily on the state.
It may be unclear how to deal with it: whether to check everything before dispatching an action or put this side-effects-related logic somewhere else.
There is a way.
We can make the middleware executor take not only action as an input but also a state. We can place the middleware after the reducer so that the middleware will always get a fresh state after reducer execution.
Then we would have the exact same set of options as we had before. We can put the side effects implementation either in Actions or Middleware making one of them thick.
ReSwift-Thunk is an example of that approach with thick Actions:
- Thunk is a kind of Action (a different name for an Async Action, basically)
- Thunk contains side effect implementation which depends on the state
- Thunk is dispatched to the store as an action
- ThunkMiddleware obtains state, intercepts thunk actions, and executes them
State-Driven Side Effects
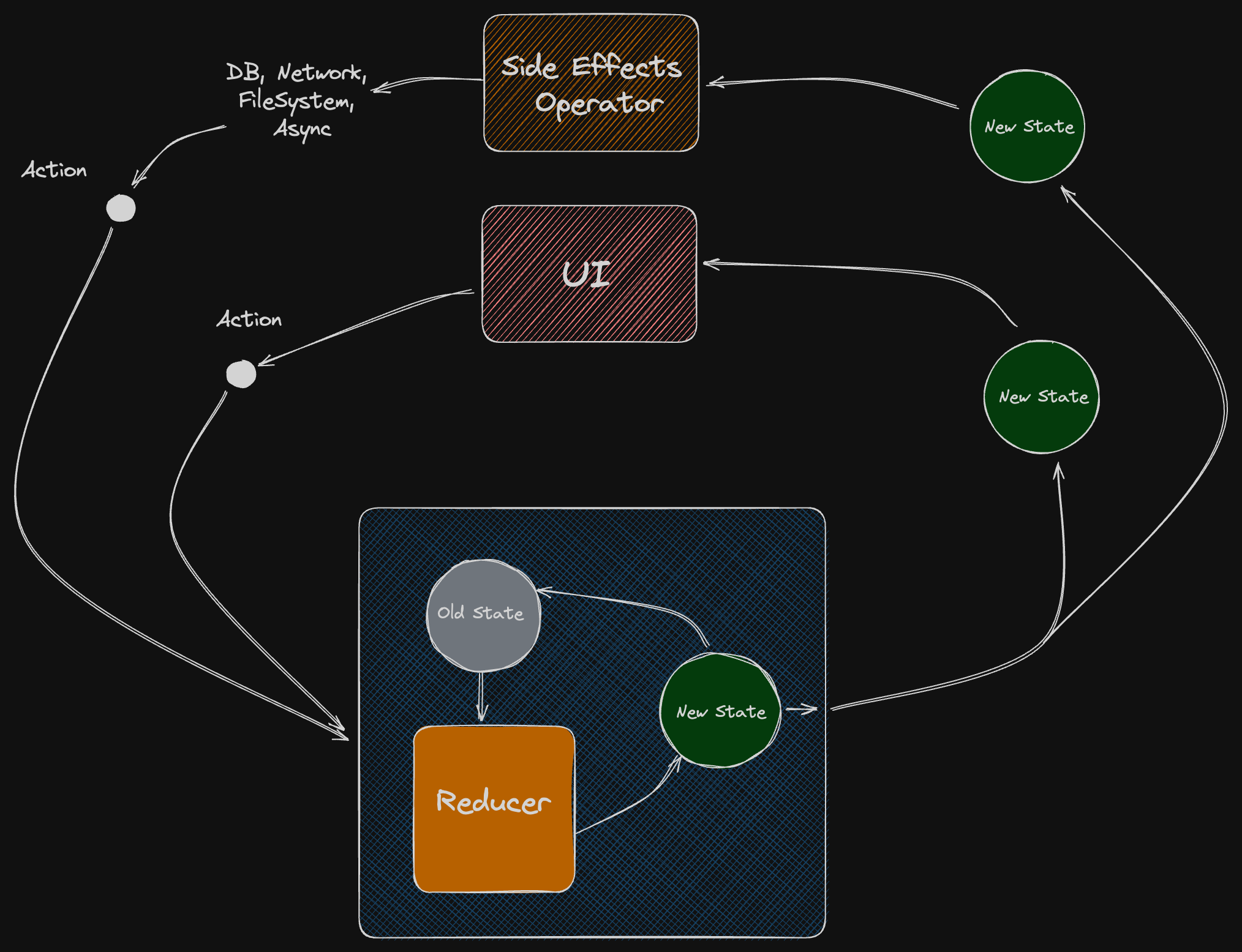
State-driven side effects implementation allows for the elimination of both middleware and sync actions.
Let's start with a SwiftUI example of a simple state with a single boolean value isLoading and a simple spinner indicator view for it with a button.
struct ContentView: View {
@State private var isLoading = 0.5
var body: some View {
VStack {
ProgressView // visible when `isLoading` is true.
.opacity(isLoading ? 1.0 : 0.0)
Button("Toggle") {
isLoading.toggle()
}
}
}
In SwiftUI the View is a function of state meaning that it's completely defined by the state.
We can imagine that the spinner is actually doing some heavy work, like spinning really hard. The work that the spinner is performing is controlled by the state: isLoading flag which may turn the spinner on/off or restart it.
From that perspective, UI can be considered a side effect as an interface to the outer world.
The idea of State-Driven side effects suggests that all side effects that the app produces can be implemented as a function of state, just like declarative UI. In that case at any point in time, the amount of async work that our app produces is completely defined by its state. It can be restated, canceled, or delayed.
There is only need to be a diffing mechanism that will compare the work which is expected to be performed with the actual work and will start/restart/cancel it when needed
Here is an example from Puredux documentation:
// Add effect state to the state
struct AppState {
private(set) var theJob: Effect.State = .idle()
}
// Add related actions
enum Action {
case jobSuccess(SomeResult)
case startJob
case cancelJob
case jobFailure(Error)
}
// Handle actions in the reducer
extension AppState {
mutating func reduce(_ action: Action) {
switch action {
case .jobSuccess:
theJob.succeed()
case .startJob:
theJob.run()
case .cancelJob:
theJob.cancel()
case .jobFailure(let error):
theJob.retryOrFailWith(error)
}
}
}
// Add SideEffect to the store in a declarative way
let store = StateStore<AppState, Action>(AppState()) { state, action in
state.reduce(action)
}
.effect(\.theJob, on: .main) { appState, dispatch in
Effect {
do {
let result = try await apiService.fetch()
dispatch(.jobSuccess(result))
} catch {
dispatch(.jobFailure(error))
}
}
}
store.dispatch(.startJob)
Reducers with Feedback Loops
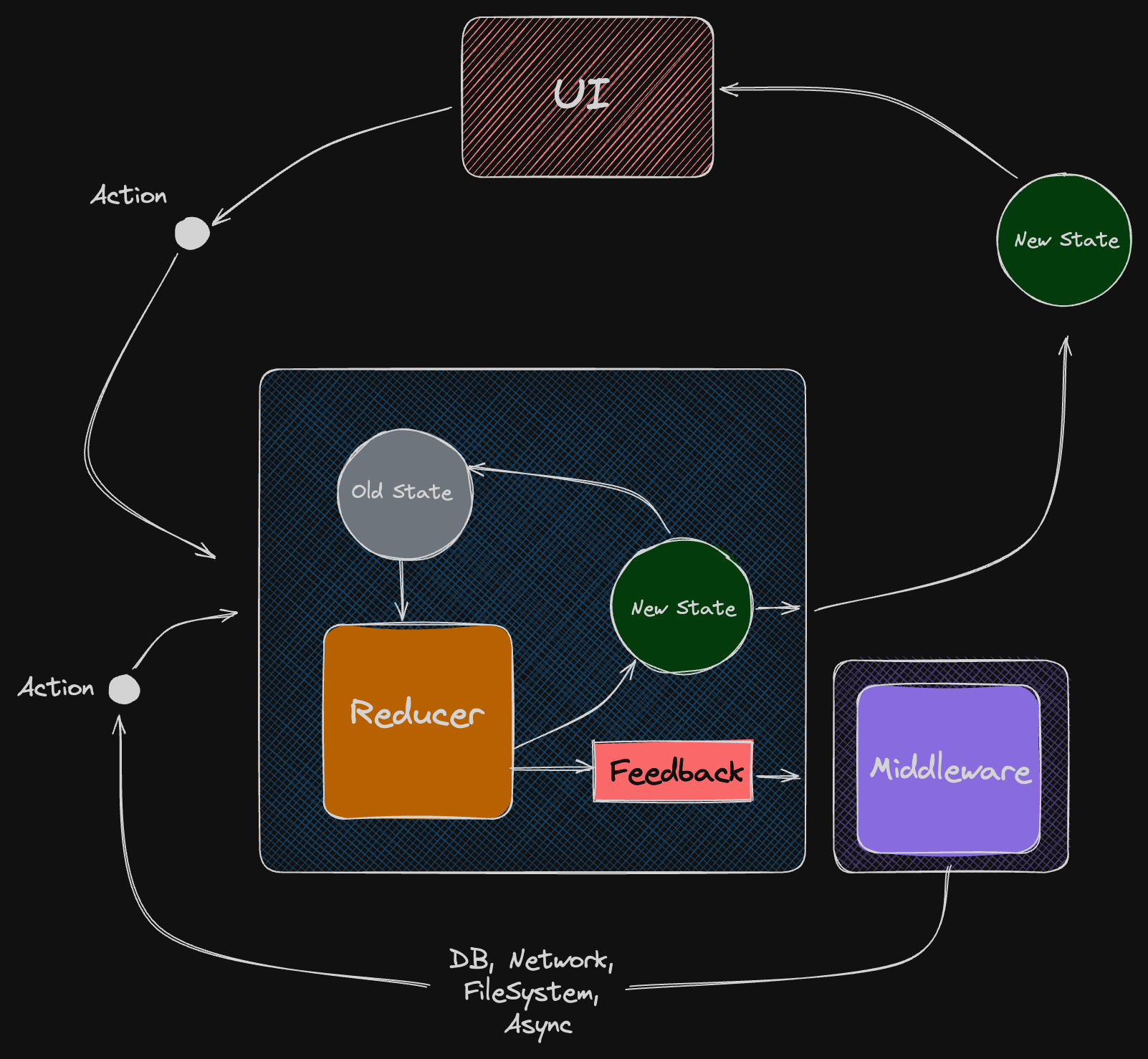
Another approach to side effects suggests making reducers more complex. We can allow them to return a new state + some feedback.
What is feedback?
It's up to implementation entirely.
It can be anything, containing instructions for executing async work. The store should be capable of executing Feedback using middleware and dispatch result actions when the task is done.
struct FetchMoviesFeedback: Feedback {
let page: Int
func execute(_ dispatch: @escaping DispatchFunction) {
let moviesService = Depencency(\.moviesService)
moviesService.fetchMoviesList(page: page) { result in
dispatch(MoviesListFetchResult(result, page: self.page))
}
}
}
extension State {
static func reduce(_ state: State, action: Action) -> (State, Feedback?) {
switch action {
case .fetchMovies:
let newState = .fetchingMovies
let feedback = FetchMoviesFeedback(page: action.page)
return (newState, feedback)
default:
return (state, nil)
}
}
}
How Different Frameworks Handle Side Effects
In the original Redux JS lib all 3 most popular side effects library rely on the middleware:
- Action creators provides encapsulation of action init process.
- React-Thunk is variation of async actions with (State, Action) Middleware.
- React Saga is an action creator that allows to build complex workflows with parallel tasks, cancellation, etc.
Here is what we have in Swift:
- TCA uses reducers with feedback loops.
- Puredux supports AsyncActions and State-Driven side effects
- RxFeedback they call it feedback but it looks more like state-driven side effects
- ReactorKit uses intercepting middleware
- Re-Swift uses Async actions with (State + Action) Middleware
- Mobius by Spotify uses reducers with feedback loops.
- SwiftRex uses plain actions with (State + Action) Middleware
- ReactiveFeedback : they call it feedbacks but it looks more like a (State + Action) Middleware
Side Effects Key Takeaways
As you can see, all approaches to handling side effects are quite similar, with components dealing with the same entities: actions, states, and sometimes feedback.
The differences lie primarily in how these components are named and their responsibilities, such as their inputs and outputs, whether they mutate state, and whether they produce side effects.
Bringing Redux-like Architecture to iOS: The Current State of Things
In 2017 when somebody talked about using Redux-like architecture in iOS, it's often considered like a weird experiment. The first time I saw Yasuhiro Inami'ss talk I thought something like:
"Well... interesting, but it seems like you're the only person in the world using it.".
Then there was a peak in hype for Redux-like architectures on iOS in 2019-2020.
Fast forward to 2024, the trend in iOS development has shifted toward building massive SwiftUI views as if everyone has forgotten the shiny promises of a future where MVI / UDF / Redux would allow us to test everything effortlessly and have no bugs.
Benefits
There is a long list of cool things that can be achieved by using MVI/Redux-like architectures on iOS because all these frameworks have a lot in common.
However, some of the benefits depend on the exact framework and its possibilities: whether it supports single-store or multiple-store configuration, how it performs side effects, and so on.
Consistency & Predictability
Unidirectional data flow and state-driven observable nature make sure that the UI is consistent with the app state.
State immutability resolves a lot of thread-safety-related problems. Being restrictive about state mutations is beneficial for app state predictability.
Functional Core, Imperative Shell
MVI frameworks encourage decoupling of the codebase into UI, Core, and Side Effects almost exactly following the [[Functional core, imperative shell]] principle. That's beneficial for the following reasons:
- Testability of the app's core business logic
- Enables independent layers development: UI, core, side effects, and API integrations
- Since you rely on a framework, you do it consistently across the codebase
That's a reliable way to keep projects maintainable in the long term.
Action is a Fortunate Abstraction
We can think about Actions as an abstraction over a function call or a transaction. Wrapping all possible mutations within the app into actions is beneficial because it's very simple to track changes:
- it's easy to spot where certain action was dispatched.
- It's easy to spot all the mutations that it produced in reducers
- Logging actions make the app literally transparent, without logs being overwhelmed
These are the things that are hard to achieve without actions with a simple function call stack.
Advanced Use Cases
If the framework supports, there is a whole bunch of advanced app infrastructure features that become possible when state and actions conform to Codable. If they are Codable, you can record, send or do whatever you wish with the app state and actions to build:
- App persistence out of the box
- Time travel, remote debugging
- App state hot-reloading for whatever purposes
- Effortless and consistent analytics
- Thanks to recording features, complicated behavioral tests can be as inexpensive as snapshot tests.
Concerns
There is a list of concerns. Some of them are common and some of them are relevant to specific implementations of MVI/Redux-like patterns and features of the exact framework.
It's Way Too Restrictive
Can we achieve the same goals without relying on third-party frameworks and fitting ourselves into their restrictions?
Some of them yes. For example, SwiftUI is unidirectional data flow out of the box but it's not restrictive about state mutations or side effects.
The irony is that MVI framework restrictions do not come out of nowhere. They are the results of the goals and features that they are trying to achieve and the problems they are trying to solve. They also try to do it in a consistent and flexible way.
And once you aim for the same features/goals/problems you have a high chance of finding yourself building a similar solution.
Performance Concerns
Performance is a huge concern of all UDF architecture frameworks.
Basically, there are 2 problems:
- Frequent UI updates
- Frequent and slow action processing due to state mutations
UI is rendered on every state change which may happen rather frequently because every action triggers it. Actions may be dispatched rather frequently while the actions processing passthrough and state mutation may be slow.
It's because of the design pattern itself that tends to centralize the state and its mutations. The extreme case is Redux with a single store for the whole app.
In practice, it all depends on how the exact framework tackles these problems. Whether it supports a multi-store configuration and granular UI updates with deduplication and debouncing,
Here is an example of Puredux's Performance tunning capabilities
Anyway, when we rely on 3rd party framework action processing and UI update cycle we at least have a place to apply optimizations. In contrast, when your app becomes irresponsive due to ObservableObjects frequent updates, you are done.
Large State Concerns
Another scalability concern is related to a huge state. The state is usually meant to be a value-type Swift struct and it's supposed to be copied every time when action is dispatched.
So what would happen in an extreme case with a single store for the whole app and a huge state?
Is Swift it shouldn't actually be a problem.
Even if you have a huge state you are likely to store your data in a normalized form in containers like Arrays or Dictionaries which implement copy-on-write semantics.
BTW Swift compiler is really sophisticated in how it optimizes structs and stores them in memory: Explore Swift Performance – WWDC24.
Architecture Scalability Concerns
Another concern is architecture scalability for large teams and large project codebases.
The key challenge is how to modularize the project both vertically and horizontally so that features can:
- Be developed independently
- Be reliably assembled into a single app and interact seamlessly
- Balance the trade-off between visibility and isolation
I believe that there is no problem with vertical scaling: Core, UI, and side effects are decoupled effectively.
Horizontal scaling capabilities depend on the exact architecture framework. Whether it supports:
- Scoped stores and actions to encourage the composition of small independent components
- Multiple stores for feature separation, and more importantly, how these stores communicate and handle side effects in a multi-store environment.
To me, it feels like Redux-like MVI architectures design does not encourage [[encapsulation]] in general and it often makes quite the opposite of the "least knowing principle" ([[Law of Demeter]]) and many other OOP-style principles like [[SOLID]] that are believed to make the codebase scalable, maintainable and so on.
This is especially evident in extreme cases where a single store is used.
It could be a drawback of the design pattern itself:
- It decouples state from side effects, exposing certain details that could otherwise be encapsulated.
- It encourages Finite-State-Machine-style programming with explicit state.
Conclusion
Everyone can now run through the infamous iOS architecture design checklist and decide if the architecture fits the following beliefs:
Is it scalable?
- Does it handle changing business requirements efficiently?
- Does it support gradual adoption in existing projects?
- Does it allow replacing third-party components easily?
- Does is encourage composition of small independent components?
- Does it allow adding UI to features later?
- Does it support breaking of retain cycles on integration rather than component level?
- Does it support people working simultaneously on different parts of a feature?
- Does it limit the use of event/notification systems to specific layers?
- Does it provide a strategy for cutting corners and tech debt?
Is it maintainable?
- Does it provide a tactic for fighting massive objects?
- Does it limit the number of dependencies for an object?
- Does it try to reduce the amount of boilerplate code?
- Does it minimize the number of different roles of components?
- Does it suggest project structure tolerant to changes?
- Does it feel right?
Is it prepared for navigation?
- Does it explain how to pass data between components?
- Does it allow describing and discovering app flow naturally?
- Does it avoid transient dependencies?
- Does it define how to store state?
- Does it minimize the amount of global state?
- Does it allow opening a stack of screens?
- Does it handle opening of a screen from a push notification?
Is it promoting quality?
- Does it maximize the amount of testable code?
- Does it encourages compile-time decisions over runtime decisions?
- Does it avoid force casting and unwrapping?
- Does it allow stubbing asynchronous code to run tests synchronously?
- Does it support testing of UI?
- Does it forgive mistakes?
Where to go from here?
I've made my own UDF Architecture framework for iOS which is called Puredux
Here is a list of most famous iOS UDF libraries for inspiration:
Comments